《深度学习入门-基于Python的理论与实现》
学习摘要
- 有兴趣可以读《计算机系统要素:从零开始构建现代计算机》
- 感知机是具有输入和输出的算法。
- 感知机将权重和偏置设定为参数
- 单层感知机只能表示线性空间,而多层感知机可以表示非线性空间
- 多层感知机可以表示计算机
《Python+Tensorflow机器学习实战》
环境搭建
wget https://mirrors.tuna.tsinghua.edu.cn/anaconda/archive/Anaconda3-5.3.0-Linux-x86_64.sh
chmod -R a+x Anaconda3-5.3.0-Linux-x86_64.sh
bash Anaconda3-5.3.0-Linux-x86_64.sh
conda create -n tf-cpu tensorflow
conda activate tf-cpu
conda deactivate tf-cpu
《Python机器学习及实践—- 从零开始通往Kaggle竞赛之路》 – 范淼、李超
简介
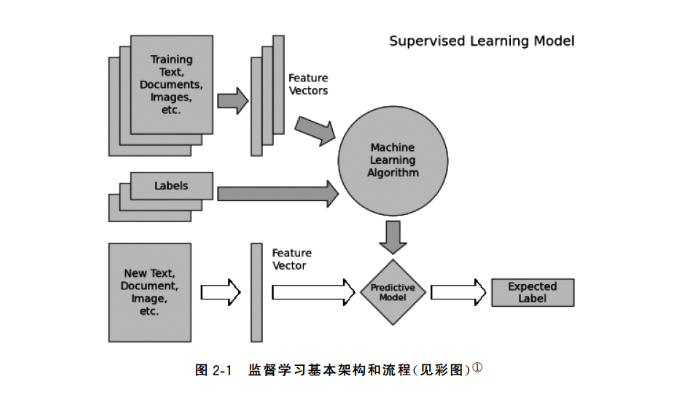
监督学习和无监督学习
监督学习关注对事物未知表现的预测,一般包括分类问题(Classification、对所在的类别进行预测)和回归问题(Regression、对连续变量进行预测)
无监督学习倾向于对事物本身特性的分析,常用的技术包括数据降维(Dimensionality Reduction、对事物的特性进行压缩和筛选)和聚类问题(Clustering、依赖数据的相似性,把相似的数据样本划分为一个簇)等
- 性能:评价所完成任务质量的指标。
基础
监督学习经典模型
《机器学习算法基础》–覃秉丰
课程链接
课程笔记
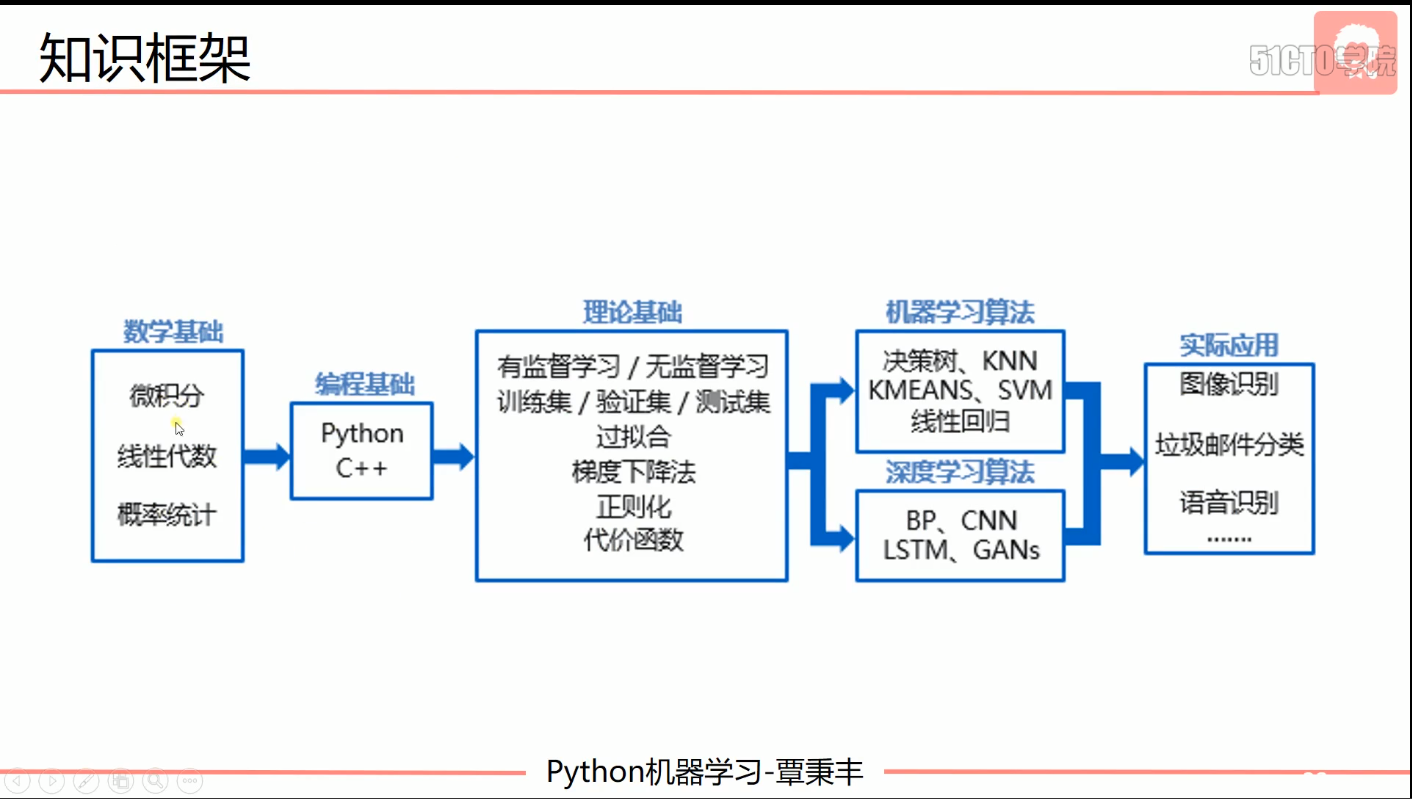
- 知识框架
- Anaconda安装Python及部分库

- 学习方式:
- 监督学习:用来训练带有标签的数据集
- 无监督学习:用来训练没有标签的数据集
- 半监督学习:监督学习和无监督学习结合的一种学习方式。主要是用来解决使用少量标签的数据和大量没有标签的数据进行训练和分类问题。
- 常见应用
- 回归
- 分类
- 聚类
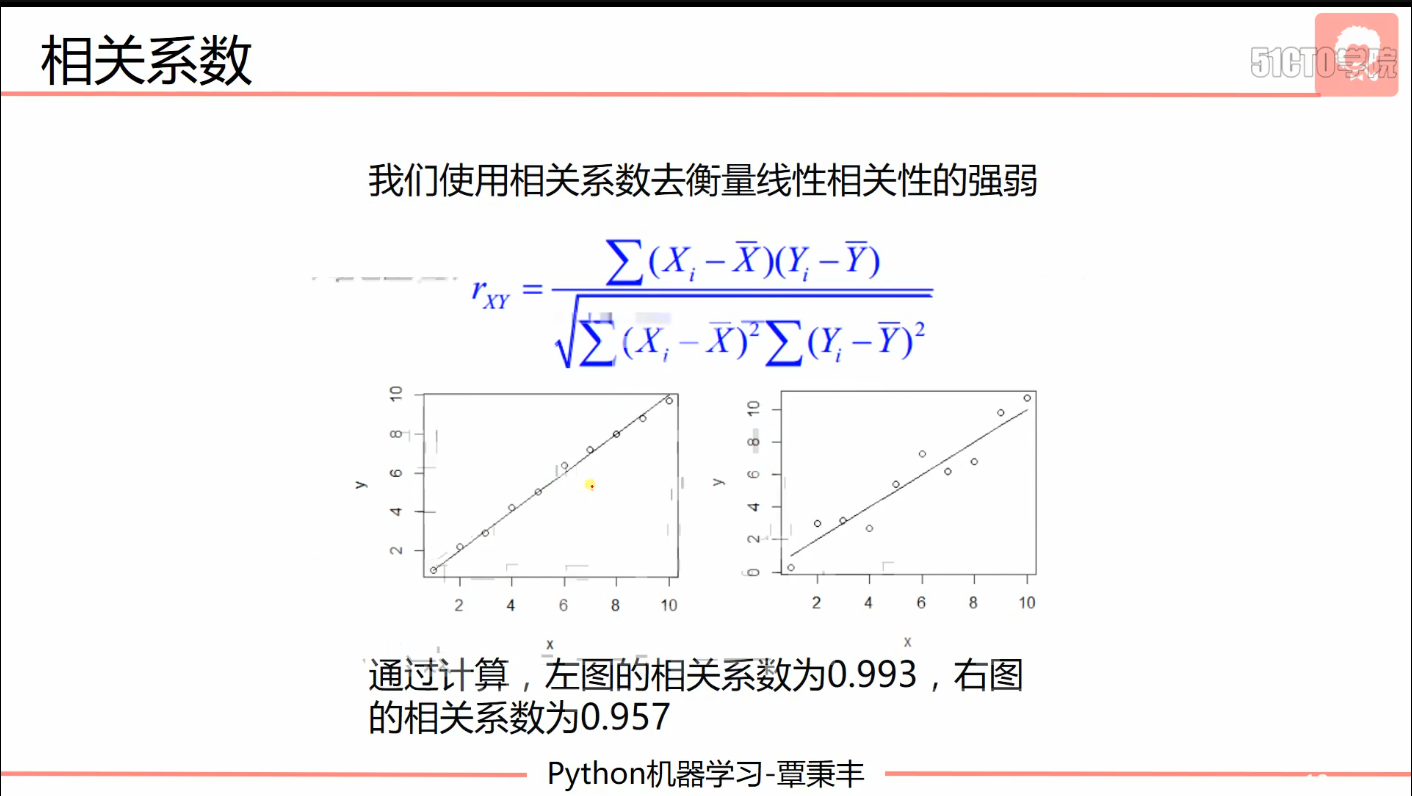
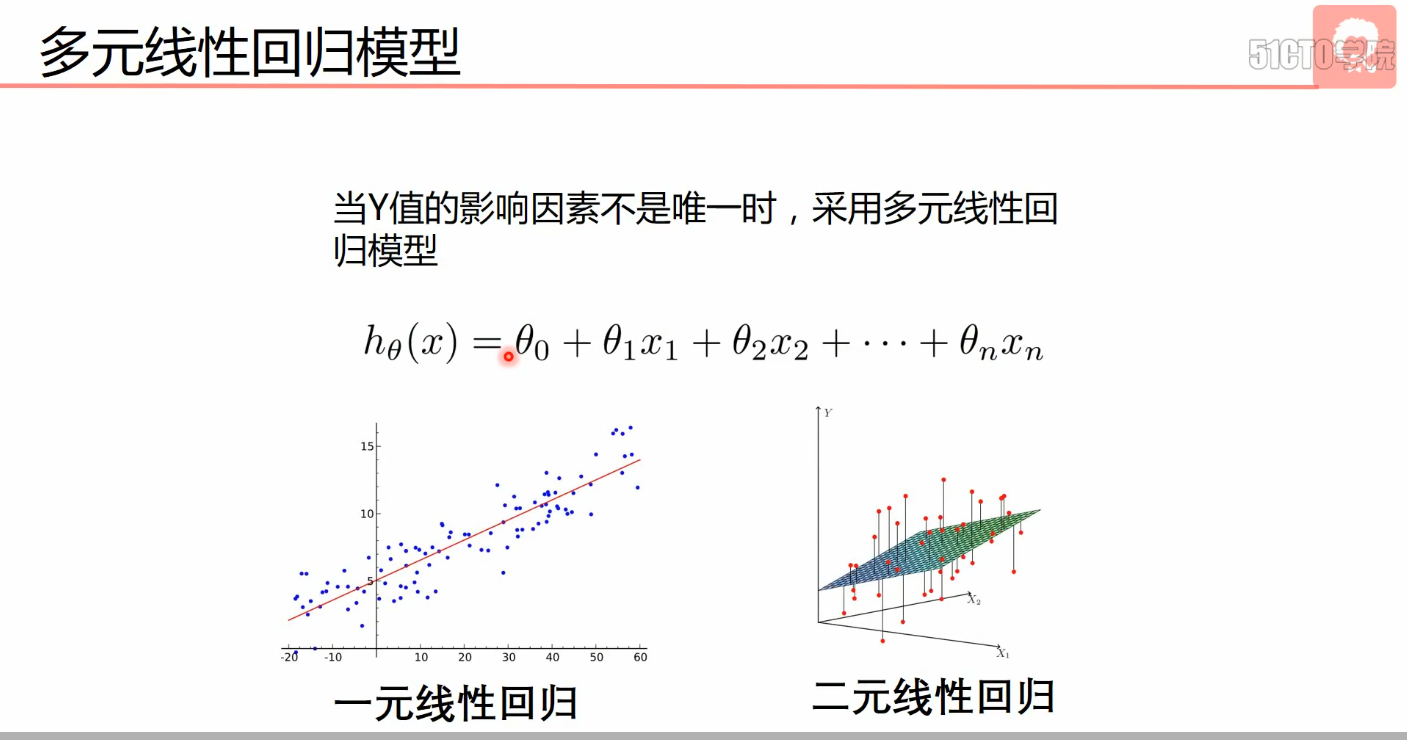
- 一元线性回归
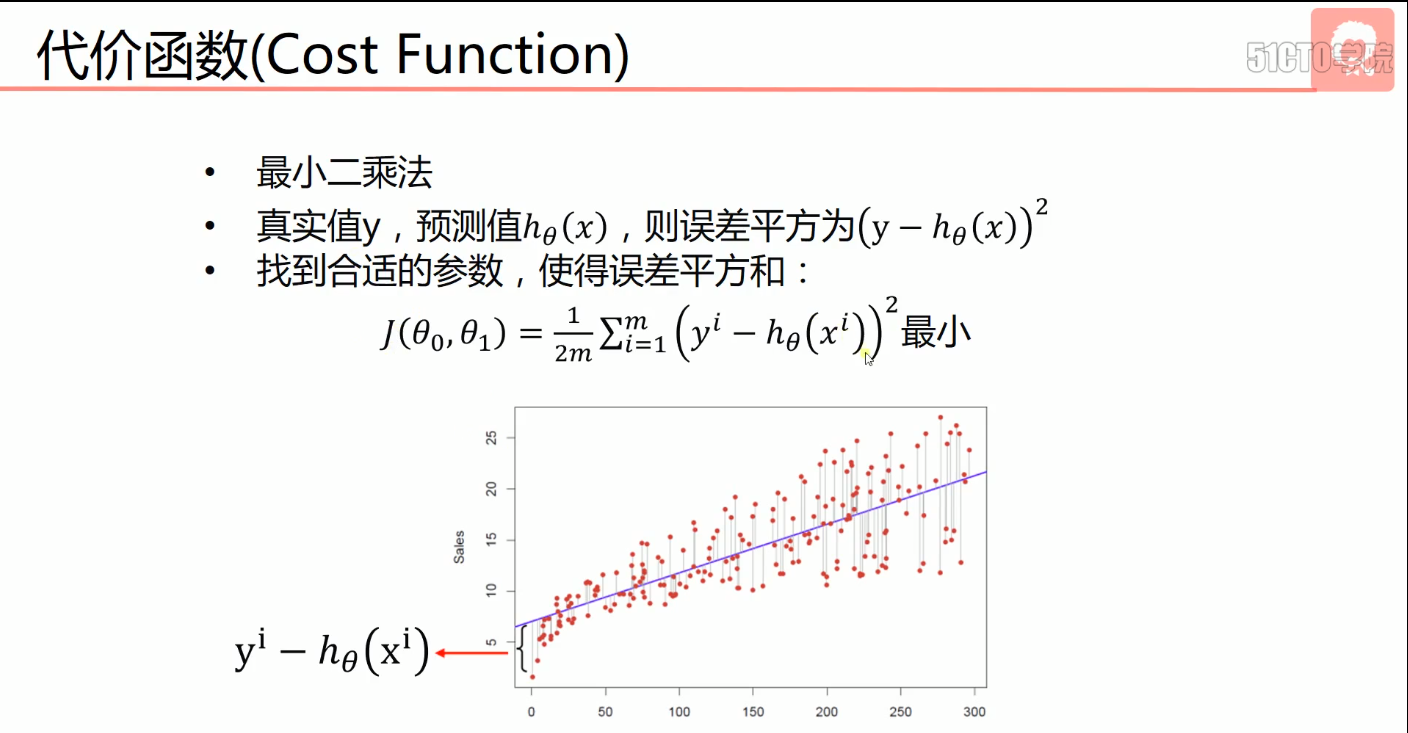
- 代价函数(Cost Function)
- 梯度下降法(优化算法)

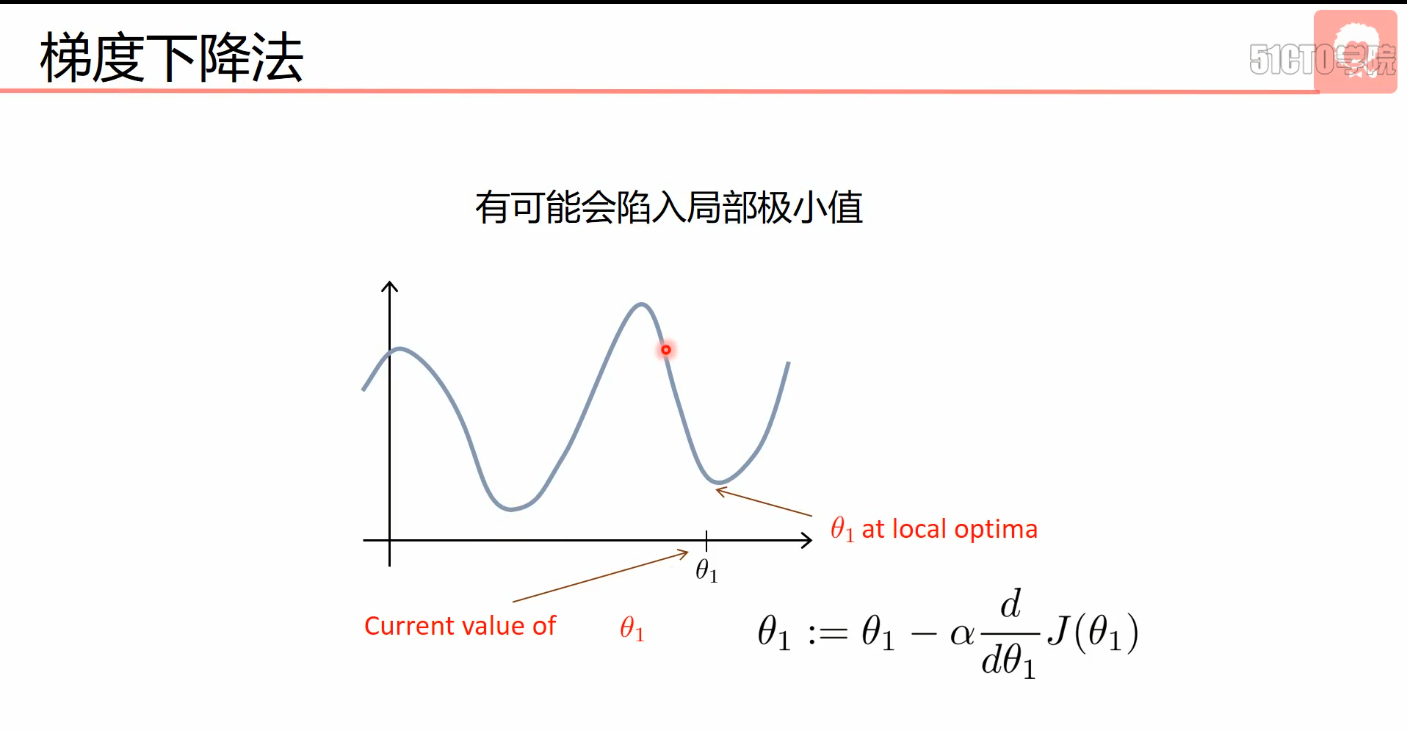


- 非凸函数使用梯度下降法可能只能获取局部最小值,线性回归是凸函数,可以使用梯度下降法
- 多元线性回归
- 多项式回归
- y=c+bt+at^2(次方数可再次增加)
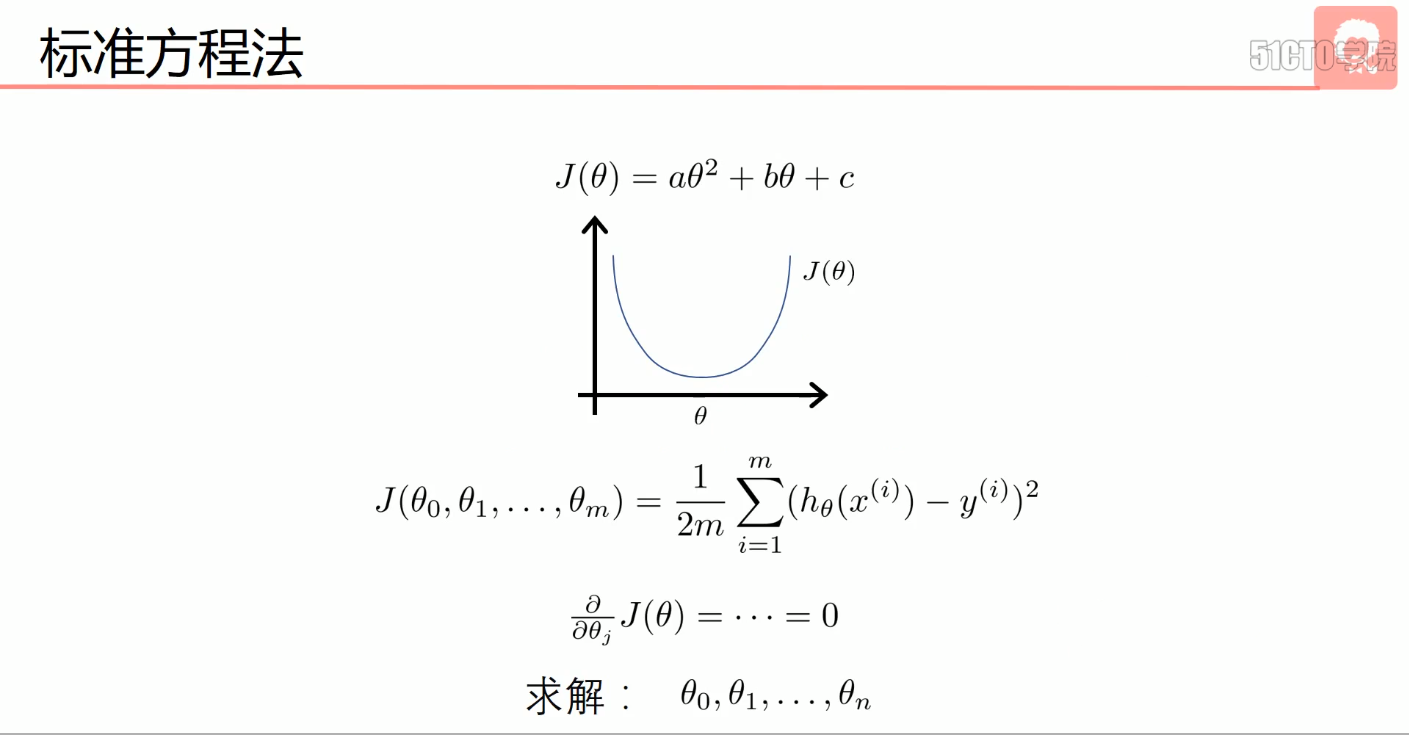
- 标准方程法
- 特征缩放
- 交叉验证法
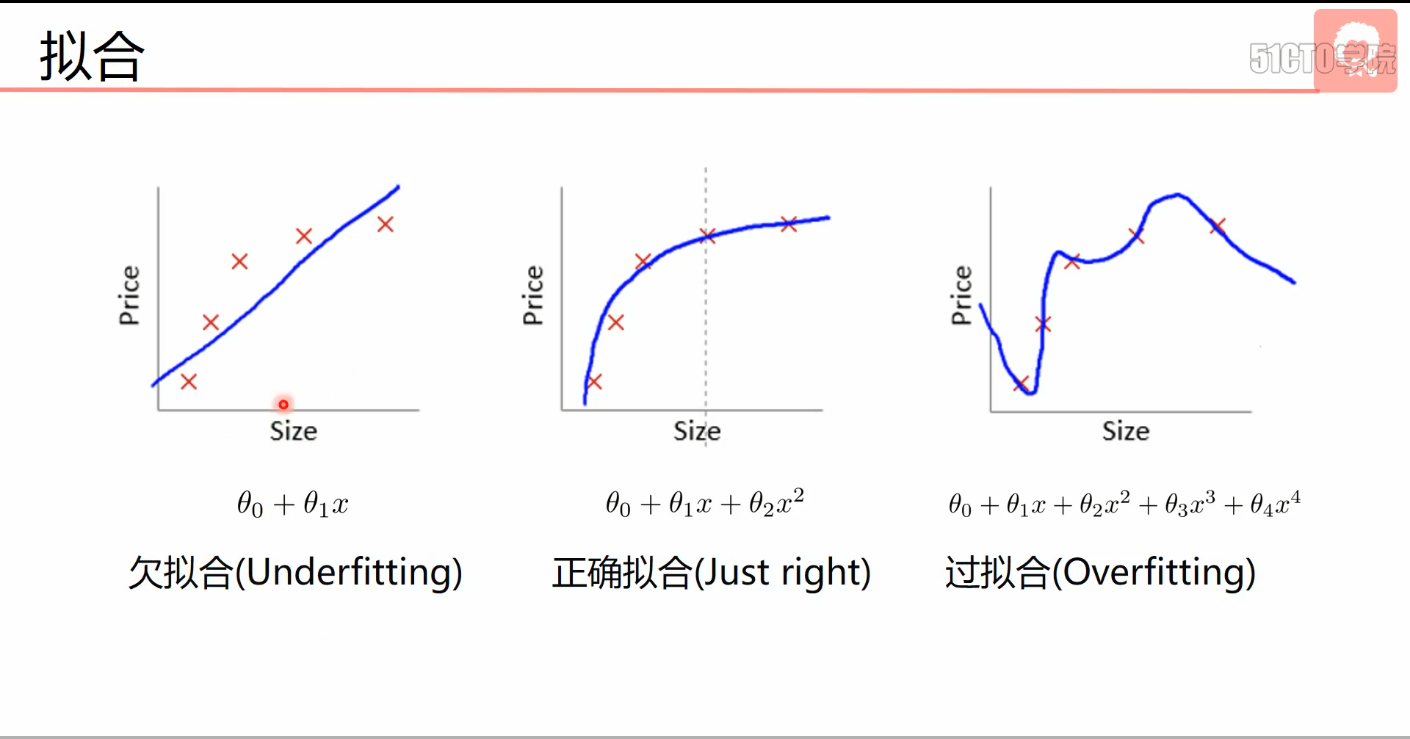
- 拟合
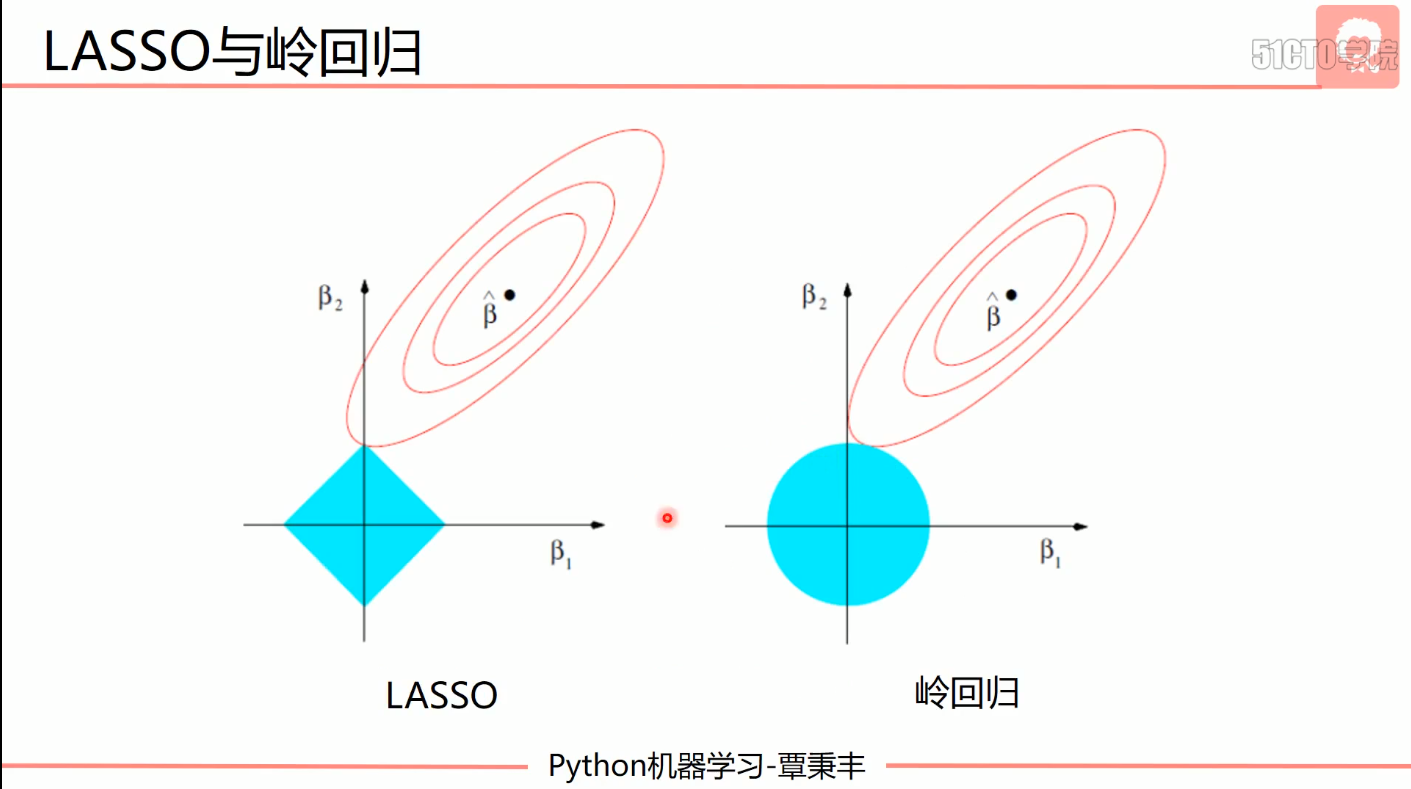
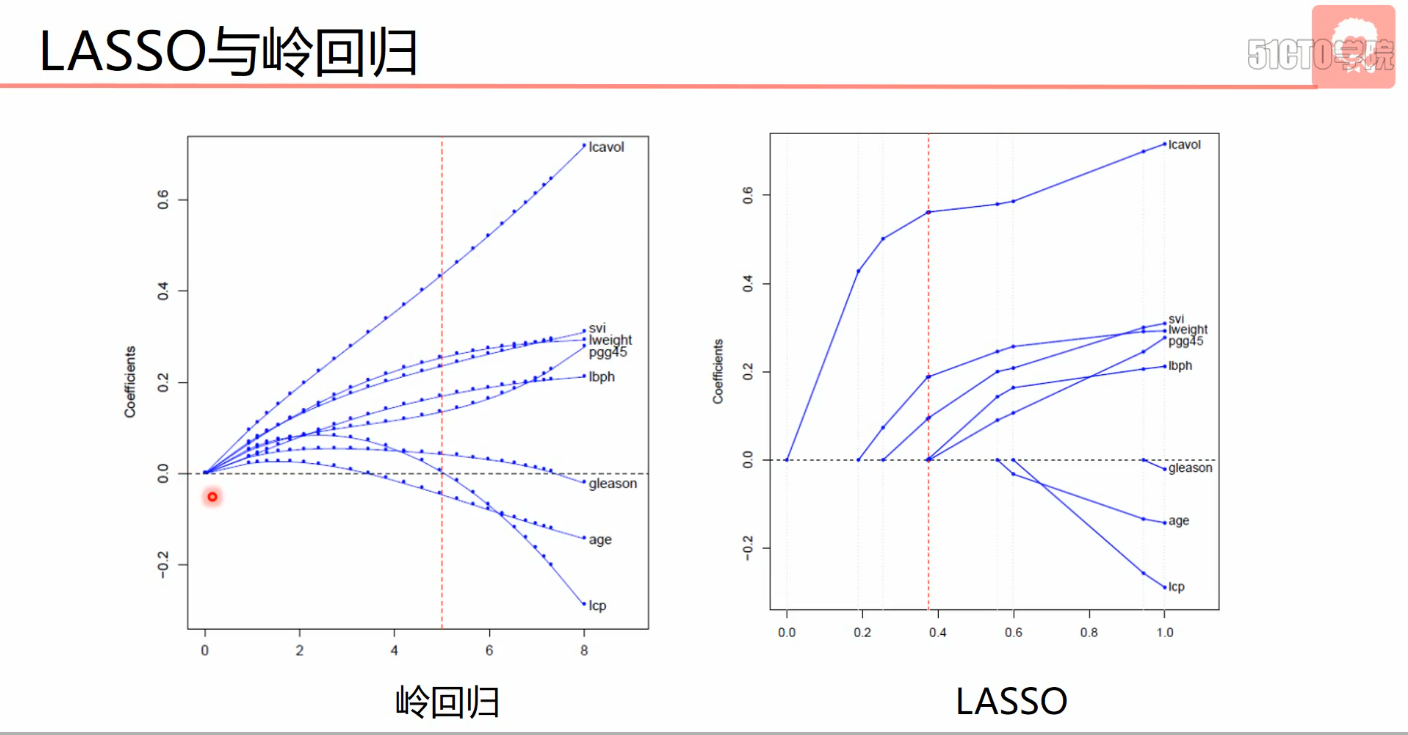
- 岭回归
- LASSO
- 弹性网-2005年提出


- 结合岭回归和LASSO














《Python3入门机器学习经典算法与应用》–慕课网
课程摘要
简介


第2章 机器学习基础
- 大写字母代表矩阵,小写代表向量

- 特征向量一般表征为列向量。行向量转置为列向量
- 图像,每一个像素点都是特征。特征可以抽象。
- 二分类和多分类:结果一个类别。
- 回归任务:结果是一个连续数字的值,而非一个类别
- 一些情况下,回归任务可以简化成分类任务,问题转化。
- 监督学习:主要解决分类和回归。
- 机器学习算法上分类:监督学习,非监督学习,半监督学习和增强学习。
- 监督学习
- 给机器的训练数据拥有“标记”或者“答案”
- 主要处理两大类:回归和分类

- 非监督学习
- 给机器的训练数据没有任何“标记”或者“答案”
- 对没有“标记”的数据进行分类-聚类分析
- 对数据进行降维处理:
- 特征提取
- 特征压缩:PCA
- 意义:方便可视化
- 异常检测
- 半监督学习
- 一部分数据有“标记”或者“答案”,另一部分数据没有
- 常见:各种原因产生的标记缺失
- 通常使用无监督学习手段对数据做处理,之后使用监督学习手段做模型的训练和预测
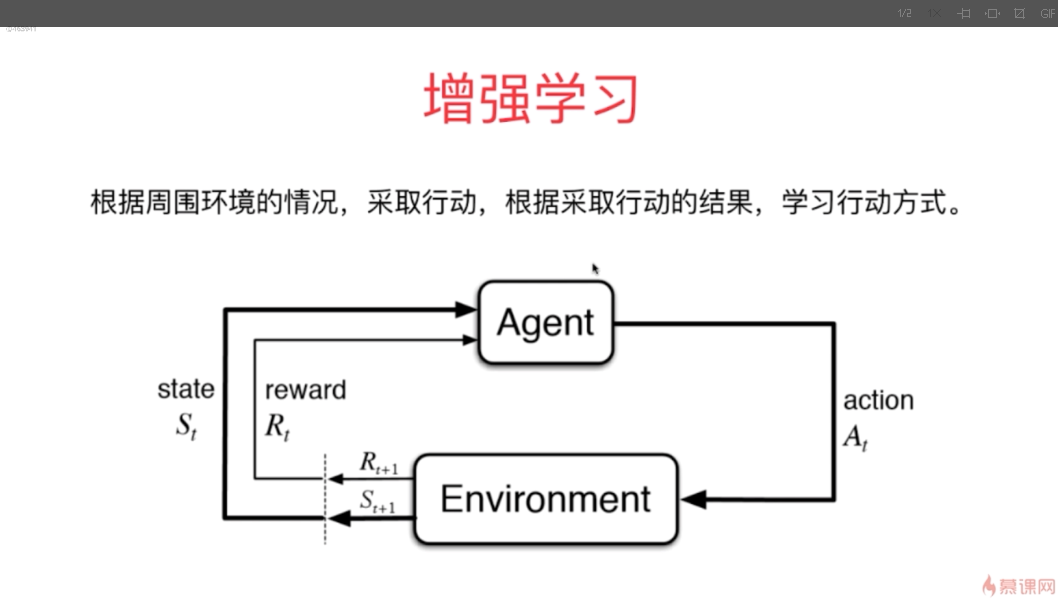
- 增强学习
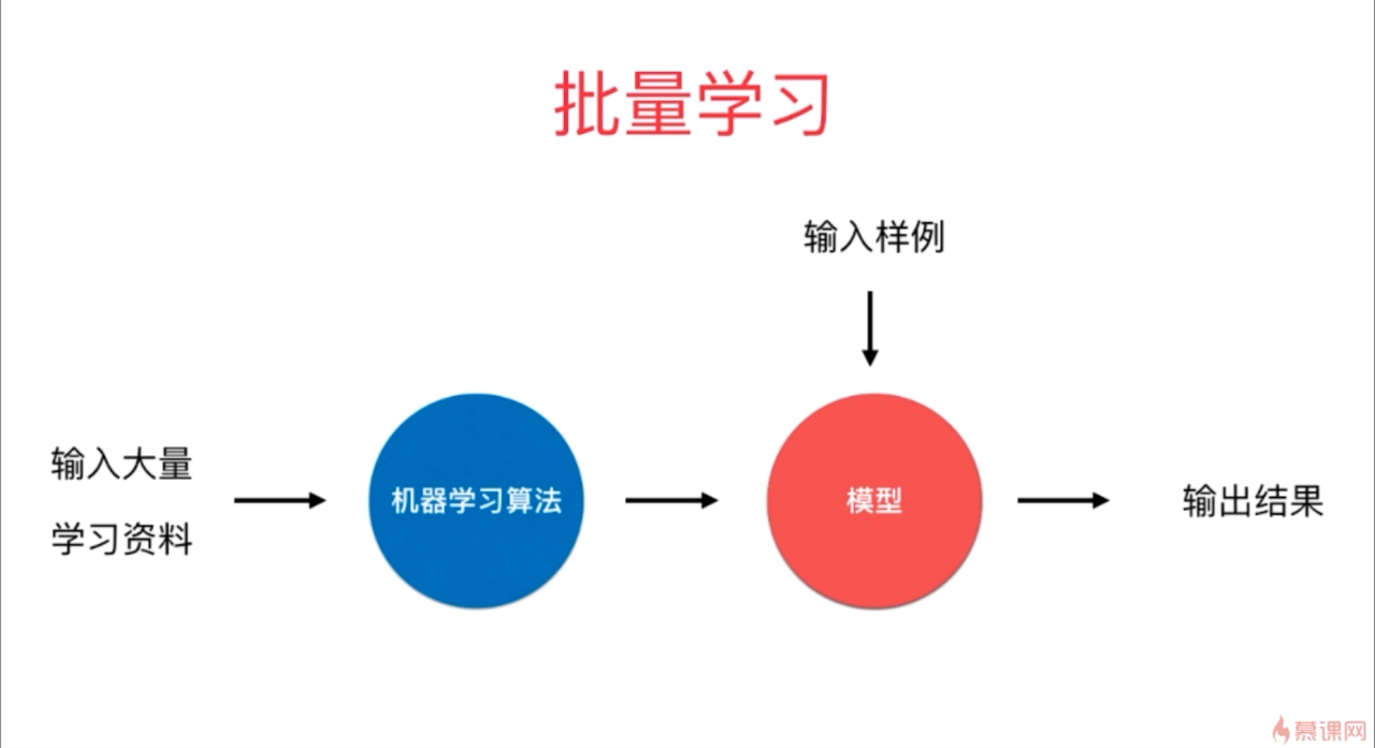
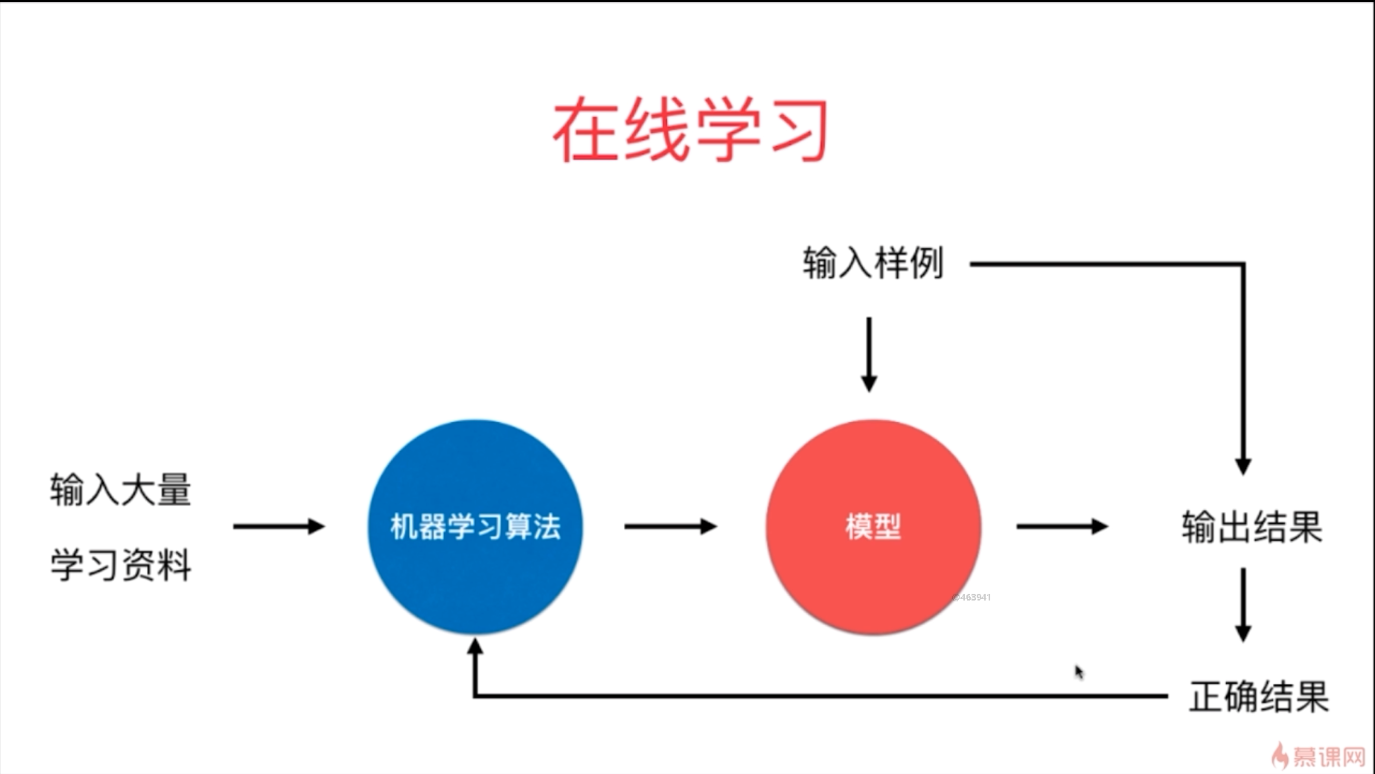
- 批量学习和在线学习
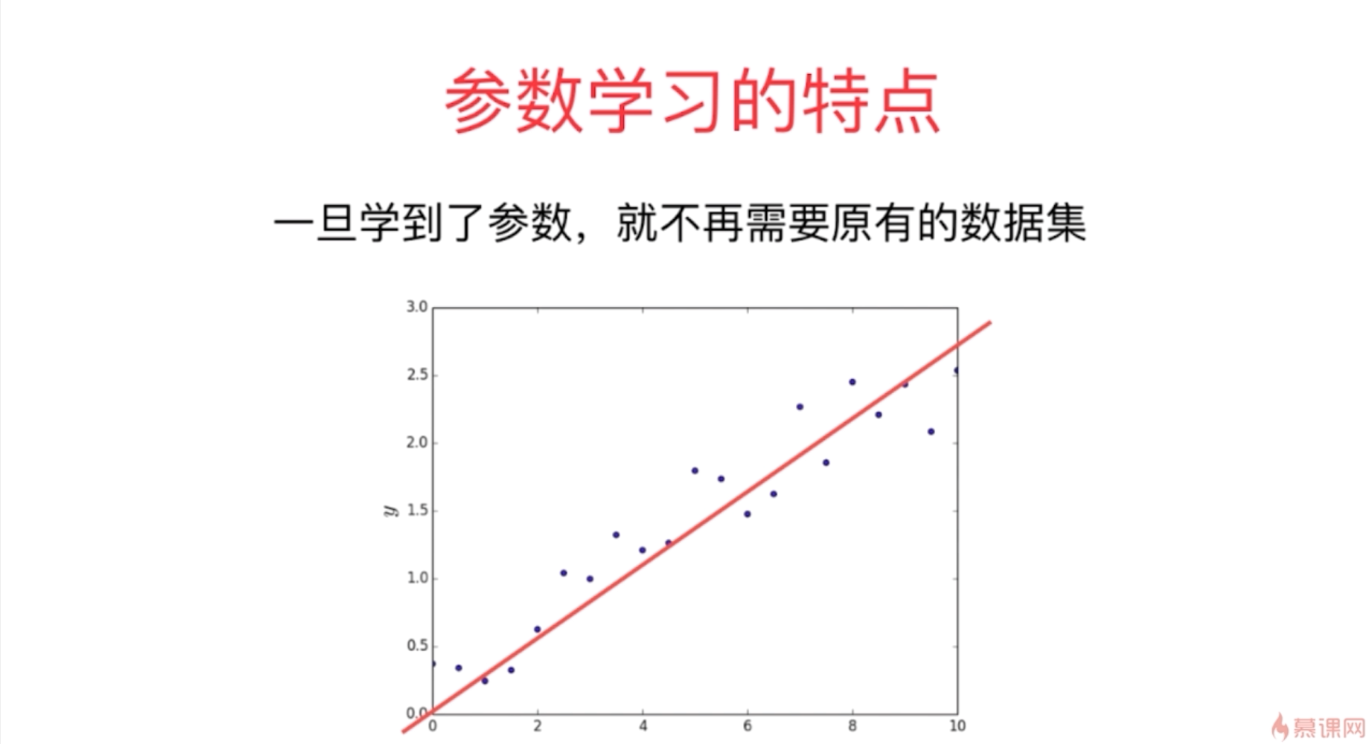
- 参数学习和非参数学习
- “哲学”思考

- 算法为王?
- 奥卡姆的剃刀—简单就是好的
- 没有免费的午餐定理—可以严格的数学推导出:任意两个算法,他们的期望性能是相同的!
- 具体到某个特定问题,有些算法可能更好。
- 没有一种算法,绝对比另一种算法好
- 脱离具体的问题,谈哪个算法好是没有意义的。
- 在面对一个具体问题的时候,尝试使用多重算法进行比对试验,是必要的
- 机器伦理学
- Numpy使用
- random、arange等接口